Unterstützen Sie den Datenzugriff im gesamten Unternehmen mit den flexiblen und erweiterten Fähigkeiten einer Data Fabric.
- Gartner-Kunde? Log in und personalisierte Ergebnisse entdecken.
Wie Data Fabric die Datenbereitstellung optimieren kann

Vereinfachung und Skalierung der Datenintegration mit der aktiven, metadatengestützten Automatisierung von Data Fabric
Leiter von Data und Analytics stehen zunehmend vor der Herausforderung, ihre wachsenden Datenassets in einer stärker verteilten Umgebung zu verwalten. Data Fabric kann helfen. Diese Präsentation bietet:
Eine Definition von Data Fabric, ihre Vorteile und die Voraussetzungen, die Unternehmen für ihre Einführung erfüllen müssen
Hilfe dazu, wie sie in bestehende Datenverwaltungs- und Datenarchitekturansätze passt
Einen schrittweisen Einblick in die Entwicklung eines zusammensetzbaren Data-Fabric-Konzepts
Schnellere und bessere Datenverwaltung mit Data Fabrics
Bewältigen Sie die Herausforderung der Verwaltung unterschiedlicher und verteilter Datenquellen mit einer Data Fabric, die Metadaten zur Automatisierung und Verbesserung von Datenverwaltungsaufgaben nutzt.
Was ist Data Fabric?
Metadaten
Data Fabric vs. Data Mesh
Data Fabric und ihre Vorteile
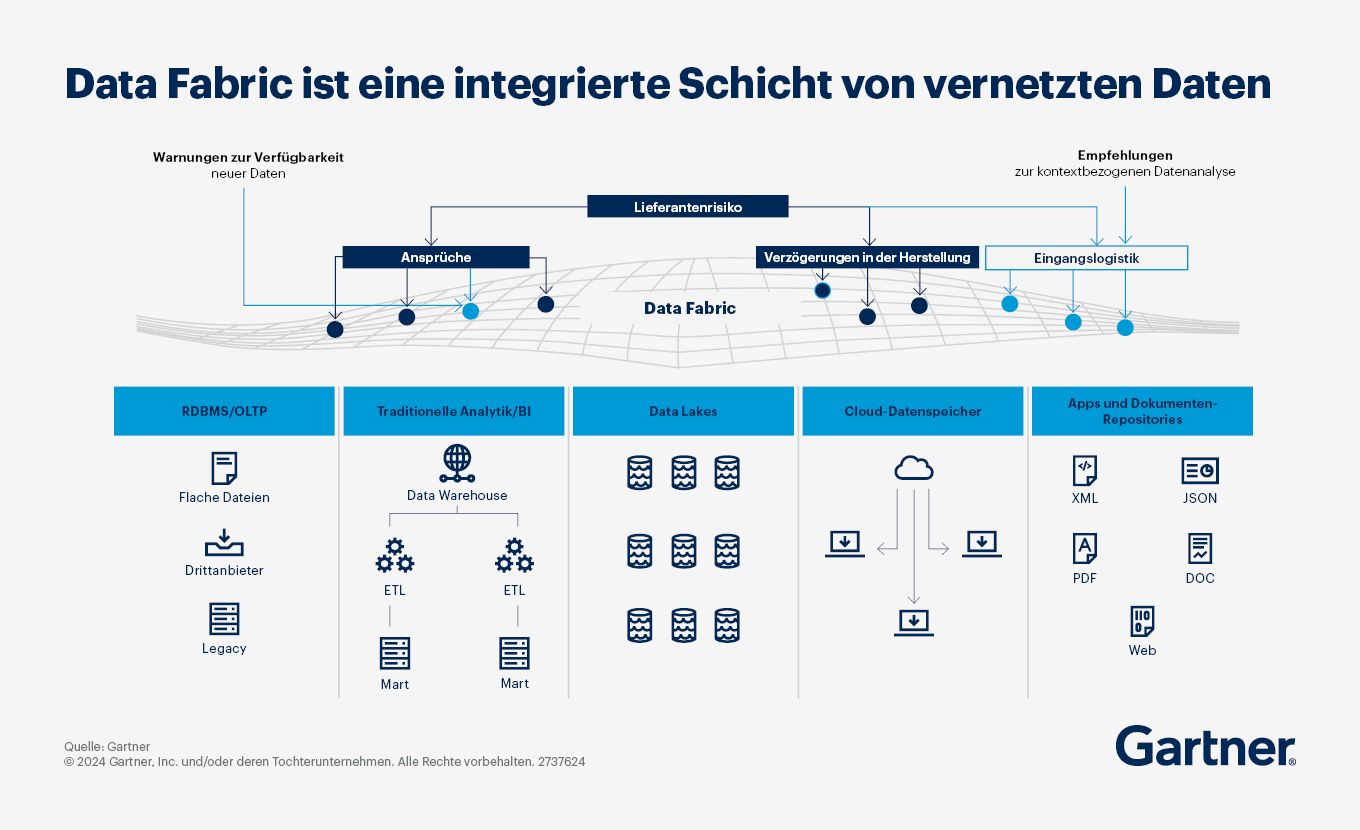
Data Fabric ist ein neues Konzept für die Datenverwaltung und Datenintegration. Ihr Ziel ist es, den Datenzugriff im gesamten Unternehmen durch eine flexible, wiederverwendbare, erweiterte und manchmal automatisierte Datenintegration zu unterstützen.
Data Fabric ist eine Lösung für die allgemeine Herausforderung, Daten aus verstreuten Datenquellen zu erfassen, zu verbinden, zu integrieren und den Nutzern zur Verfügung zu stellen, die sie benötigen. Vor dem Hintergrund zunehmender Daten- und Anwendungssilos und begrenzter Data- und Analytics-Talente verspricht die Data Fabric, die Datenintegrationsinfrastruktur des Unternehmens zu vereinfachen und eine skalierbare Lösung zu schaffen, die die technischen Schulden reduziert (siehe auch Modernisierung des Datenmanagements zur Wertsteigerung und Kostenreduzierung).
Die Kernkompetenzen der Data Fabric
In ihrer einfachsten Form erfasst eine Data Fabric Metadaten von beteiligten Systemen und Nutzern, analysiert sie und erstellt Warnungen und Empfehlungen, die aufzeigen, wie Daten besser organisiert, integriert, mit Bedeutung versehen und verwendet werden können, um die Nutzererfahrung und Geschäftsergebnisse zu verbessern.
Die Vorteile der Data Fabric
Data Fabric ist für viele Unternehmen interessant, weil sie vorhandene Metadaten und Infrastrukturen wie logische Data Warehouses nutzt. Bei einem Data-Fabric-Konzept gibt es kein „Entfernen und Ersetzen“. Stattdessen können Unternehmen Data Fabrics zur Erweiterung (oder vollständigen Automatisierung) des Konzepts und der Bereitstellung der Datenintegration nutzen und dabei aus den in vorhandene Data Lakes und Data Warehouses gesteckten Kosten Kapital schlagen.

Obwohl Data Fabric noch keine ausgereifte Technologie ist und derzeit kein Einzelanbieter alle Data-Fabric-Komponenten anbietet, können verschiedene Bereiche des Unternehmens die potenziellen Vorteile nutzen, z. B.:
Geschäftsbereiche – Ermöglicht nichttechnischen Geschäftsanwendern das schnelle Auffinden, Integrieren, Analysieren und Freigeben von Daten.
Datenverwaltungsteams – Bietet Produktivitätsvorteile durch automatisierten Datenzugriff und -integration sowie erhöhte Agilität für Dateningenieure, was eine schnellere Bereitstellung von Datenanforderungen zur Folge hat.
Gesamtes Unternehmen – Bietet schnelleren Erkenntnisgewinn durch Investitionen in Data- und Analytics, bessere Nutzung von Unternehmensdaten und geringere Kosten durch Erkenntnisse zur effektiven Datengestaltung, -bereitstellung und -nutzung.
Eine effektive Data-Fabric-Implementierung beginnt mit Metadaten
Data Fabric stützt sich auf Metadaten, d. h. „Daten im Kontext“, die das kontextbezogene Was, Wann, Wo, Wer und Wie der Daten im Unternehmen dokumentieren. Metadaten entstehen als Nebenprodukt der Datenbewegung in Unternehmenssystemen.
Es gibt vier Arten von Metadaten: technische, betriebliche, geschäftliche und soziale. Bei jeder dieser Arten kann es sich entweder um „passive“ Metadaten handeln, die von Unternehmen erfasst, aber nicht aktiv analysiert werden, oder um „aktive“ Metadaten, die Aktionen in zwei oder mehr Systemen identifizieren, die dieselben Daten verwenden. Per Definition wandelt eine Data Fabric passive in aktive Metadaten um.
Entwicklung einer zusammensetzbaren Data Fabric
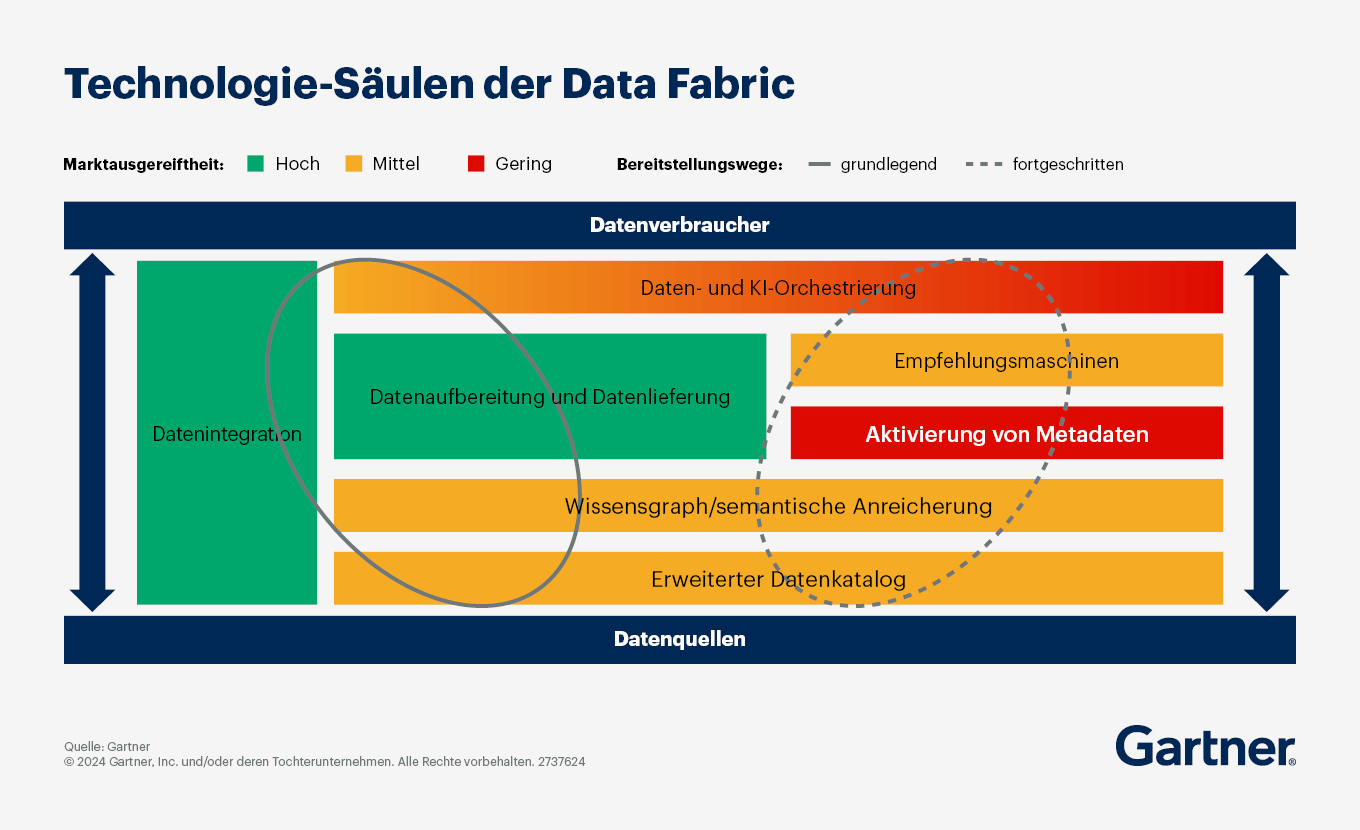
Der erste Schritt besteht in der Erweiterung eines Datenkatalogs. Data Fabrics sind zusammensetzbar, d. h. sie bestehen aus mehreren technischen Komponenten, die Unternehmen miteinander kombinieren können. Eine der Komponenten ist ein erweiterter Datenkatalog. Dabei wird KI/ML eingesetzt, um eine Verbindung zu verschiedenen Datenquellen herzustellen und diese zu finden, zu markieren und mit Anmerkungen zu versehen. Der daraus resultierende Datenkatalog enthält ein Inventar der verteilten Datenassets und der zugehörigen passiven Metadaten. Außerdem hilft er Stakeholdern bei der Zusammenarbeit im Bereich Data-Governance und erleichtert die Kommunikation über gemeinsame Semantiken im Zusammenhang mit Daten aus verschiedenen Quellen.
Der nächste Schritt besteht in der Aktivierung der erfassten Metadaten durch die Durchführung von Graphenanalysen und die Verwendung der Ergebnisse zum Trainieren eines KI/ML-Modells zur Automatisierung von Datenintegrations- und Datenverwaltungsaufgaben. Auf dieser Grundlage können Data- und Analytics-Teams Wissensgraphen erstellen, die Verbindungen zwischen den verschiedenen Datenassets des Unternehmens und ihren Benutzern aufzeigen.
Schließlich können Unternehmen ihre Wissensgraphen mit Semantik anreichern, also mit der geschäftlichen Bedeutung und den Beziehungen in den Daten. Semantik auf der Grundlage von Wissensgraphen ermöglicht bessere Analysen und fundiertere KI/ML-Modelle.

{kind=link}
{kind=link}
Wenn diese Schritte abgeschlossen sind, können die ML-Engines der Data Fabric damit beginnen, bestimmte Datenintegrationsaufgaben und Datenverwaltungsaktivitäten mit Informationen anzureichern und zu automatisieren. Je nach Ausgereiftheit der Data Fabric wird der Grad der Automatisierung wie folgt fortschreiten:
Engagement – Ermöglichen Sie es beispielsweise weniger qualifizierten Integratoren, Datenquellen zu finden und zu integrieren, oder Fachleuten, die semantische Suche zu nutzen, um Daten besser zu verstehen.
Erkenntnisse – Ermöglichen Sie z. B. automatisiertes Tagging und Annotieren, dynamische Schemaerkennung, Erkennung und Reporting von Anomalien, Hervorhebung sensibler Attribute für die DSGVO usw.
Automatisierung – Ermöglichen Sie z. B. die automatische Korrektur von Schemaabweichungen, integrieren Sie die „nächstbesten“ Datenquellen automatisch, empfehlen Sie optimale Transformationen und fördern Sie die Selfserviceintegration in Produktionsumgebungen.
Data Fabric und Data Mesh sind unabhängige Konzepte, die nebeneinander bestehen können
Die Begriffe „Data Fabric“ und „Data Mesh“ werden häufig synonym verwendet oder sogar als konkurrierende Ansätze diskutiert. Tatsächlich handelt es sich um unabhängige Konzepte. Unter den richtigen Umständen können sie sich gegenseitig ergänzen.
Zusammenfassend lässt sich sagen, dass Data Fabric ein neues Datenverwaltungskonzept ist, das Metadaten zur Automatisierung von Datenverwaltungsaufgaben und zur Beseitigung manueller Datenintegrationsaufgaben verwendet. Data Mesh hingegen ist ein architektonischer Ansatz mit dem Ziel, geschäftsorientierte Datenprodukte in Umgebungen mit verteilten Datenverwaltungs- und Data-Governance-Verantwortlichkeiten zu entwickeln.
Obwohl es bei Data Fabrics um die Datenverwaltung und bei Data Mesh um die Datenarchitektur geht, verfolgen beide das gleiche Ziel, nämlich einen leichteren Zugang zu Daten und deren Nutzung zu ermöglichen.
Einige wichtige Unterscheidungen und Ergänzungen sind:
Technologie – Eine Data Fabric kann mit verschiedenen Integrationsstilen in Kombination funktionieren, um eine metadatengesteuerte Implementierung und Gestaltung zu ermöglichen. Ein Data Mesh ist eine Lösungsarchitektur, die die Gestaltung innerhalb eines technologieunabhängigen Frameworks leiten kann.
Zweck – Eine Data Fabric entdeckt Möglichkeiten zur Datenoptimierung durch die kontinuierliche Nutzung und Wiederverwendung von Metadaten. Ein Data Mesh nutzt das geschäftliche Fachwissen von Unternehmen, um kontextbezogene Datenproduktdesigns zu entwickeln.
Datenautorität und Data-Governance – Eine Data Fabric erkennt und verfolgt Datenverwendungsfälle, die maßgeblich sein können, und behandelt alle nachfolgenden Wiederverwendungen, indem sie die Datenautorität je nach Verwendungsfall ergänzt, verfeinert und auflöst. Ein Data Mesh legt den Schwerpunkt auf die ursprünglichen Datenquellen und -verwendungsfälle, um kombinatorische Datenprodukte für bestimmte Geschäftskontexte zu erstellen.
- Menschen – Eine Data Fabric fördert eine erweiterte Datenverwaltung und plattformübergreifende Orchestrierung, um den menschlichen Aufwand zu minimieren. Ein Data Mesh fördert derzeit die kontinuierliche manuelle Gestaltung und Orchestrierung bestehender Systeme mit menschlichem Eingriff bei der Wartung.
Abwägung der Kosten von Data Fabric vs. Data Mesh
Data- und Analytics-Leiter werden letztendlich die Kosten für die Modernisierung durch Data Fabric und/oder Data Mesh abwägen müssen. Ganz gleich, welches der beiden Systeme eingesetzt wird, können die jeweiligen Gesamtkosten in Bezug auf die Entwicklung und Bereitstellung ähnlich sein. Die erweiterten Datenverwaltungsfunktionen, die in einer Data Fabric enthalten sind, verbessern jedoch das Kostenmodell für die kontinuierliche Verbesserung, Wartung und Data-Governance.
Darüber hinaus stützt sich die Data Fabric stark auf bestehende technologische Tools und Plattformen. Ein Mesh hingegen verlagert den Schwerpunkt der Kosten auf die Bereitstellung von Datendiensten. In der Cloud-Ära sollten die Datenkosten und die Abonnementflexibilität ebenso berücksichtigt werden wie aktuelle Nutzungsmuster und etwaige Richtungsänderungen im Budget und im Zuweisungsverhalten.